コインを投げて表が出るか裏が出るか賭けをするとします。表裏が出る確率が同じときには、表に賭けても裏に賭けてもアタリハズレは半々です。では、表と裏で出る確率が異なる場合(仮に表が出る確率を 
最適な賭け方
正解は「確率の高い方に賭ける」です。数式で書くと 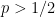



実はこの場合も先程と同様「
まず、実際にコインの表裏が出る2通りと表裏に賭ける2通りで、計4通りの場合が起こる確率を表にしてみます。
| 表が出る | 裏が出る | |
|---|---|---|
| 表に賭ける |  |
 |
| 裏に賭ける |  |
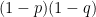 |
アタリになる場合は「表が出て、表に賭ける」ときと「裏が出て、裏に賭ける」ときの2通りなので、当たる確率は 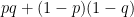
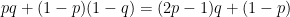
すると、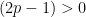
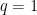
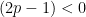
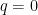

ここで2点注意しておきます。まず、ここまでの話はコインの表が出る確率(同じことですが裏の出る確率)が分かっていると仮定しています。次に、最適な賭け方をしても一定の確率で外れます。これは表裏が出るかは確率的に決まる以上仕方のないことです。重要なのは一定の確率で外れるけれどもこれが最適、つまり、これ以上当てる確率をあげることはできない、ということです。
最適予測とベイズエラー
話を機械学習に移します。大雑把に言って機械学習では何かしらの入力 

いま仮に入力(画像)が与えられたときの出力(猫がいるかいないか)の確率が 

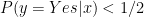
先ほどのコインの話の最後に強調したことは、この場合にも同様に当てはまります。つまり、最適な予測をしても一定の確率で予測は外れます。外れますが、これ以上予測精度をあげることはできません。この「最適な予測をしたときに外れる確率」をベイズエラーといいます。
ベイズエラーは予測精度の限界値を与えるもので理論上大変重要な概念です。もう一度繰り返しますが、何をどうやっても、深層学習を使おうが、最先端のなんとか学習を使おうが、量子計算しようが、シンギュラリティが来ようが、予測は必ずベイズエラーより大きい確率で間違いは起こります。
かんじんなことは、計算できないんだよ
それほど重要なベイズエラーですが機械学習の教科書で説明されないことも多いようです。(記事の最後で、そこら辺も説明してあるおすすめの教科書を紹介します。)その原因は、ベイズエラーを実際に計算できることは現実の問題でまずない、という点にあります。
ベイズエラーを計算するためには 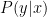
とはいえ、ベイズエラーの概念を理解しておくことは機械学習システムの研究開発をする際に大いに役に立ちます。たとえば、学習結果を評価した結果、期待するほど予測精度が高くなかった場合、モデルや訓練方法に問題があるのではなく、そもそもベイズエラーが大きいデータなのではないかと疑ってみることは重要です。
広く使われているベンチマークテストでは、そういった問題は既によく知られている(はず)なので、あまり気にしなくて良いかもしれませんが、自分で作った新しいデータではベイズエラーの高さを疑ってみることは重要です。ベイズエラーが大きいデータの場合、いくらモデルや訓練方法を工夫してもある程度以上は予測精度が向上することはなく、素性の取り方やラベルの種類などを見直さないと根本的な解決にはなりません。
一つ注意したいのは、予測したいことによっては、本質的に出力が入力に一意に定まらない場合があることです。たとえば、「食べ物の写真」を入力として「食べた人が美味しいと思ったかどうか」を 予測しようとする場合を考えます。美味しいかどうかは食べてみないとわからないですし、味の好みは人それぞれです。なので、いくら入力の写真を解析しても、いくら沢山のデータを集めても、写真だけから当てることは極めて難しく、ベイズエラーはそれほど小さくないことが予想できます。このような場合、何をどう頑張っても予測精度には限界があります。(主観的な判断が必要とされる問題は、このようなことが起こることが多い気がします。)
ベイズエラーを(粗く)近似する
現実の問題でベイズエラーが正確に計算できることはまずありません。しかし、その感触をつかむためにいくつか試せることがあります。
まず、


入力変数が多次元の場合(ほとんどの機械学習の問題はそうです)、

この場合、残す次元 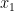
先ほどの場合と同様、
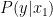
適切なベースラインを使おう
機械学習の結果を報告するときは、単に提案した手法の結果だけでなく、比較対象となるベースライン手法を用意してその結果も報告することが通例です。広く使われているベンチマークデータを使う場合には既存手法も沢山あるので、その中から適当なものを選んでくることが多いですが、新しいデータの場合そうもいかないことがあります。その場合でも、適当なベースライン手法を用意することは問題の難しさや提案手法のインパクトを説明するうえで重要です。
ベースライン手法を自分で作るのはなかなか難しいことです。いい加減な方法をとってしまうと、提案手法がよく見えるようにわざと弱いベースラインを使ったのではないか、と疑われてしまいます。かといってヘンに凝ったことをやって、そもそもそれが問題を解くのに適切な手法なのか、と疑問に思われても本末転倒です。理解しやすくかつ妥当な精度を出す(と合理的に期待される)手法を選ばないといけません。
ひとつの手は、上で説明した近似ベイズエラーから決定則をつくり、それをベースラインとして用いることです。具体的には
(余談ですが、文書要約の基礎技術として記事の中から要約に含むべき文を選ぶ「文選択」というタスクがあります。とある文選択のベンチマークテストでは「記事の先頭に近い文から選ぶ」というベースラインを越えるのは簡単ではないことが知られています。)
学会などで、とても凝った手法を散々試しているわりに、このような簡単に構成できるベースラインの評価をしていない機械学習研究を時折見かけます。自分のアイデアをいろいろ試したくなる気持ちはよくわかりますが、まずはデータの基本的な性質をきちんと理解するところから始めるべきだと思います。
おまけ:おすすめの機械学習の教科書

「わかりやすいパターン認識」という20年近く前に出た本で、深層学習どころかサポートベクトルマシンも載っていませんが、機械学習の基礎固めをするのにおすすめの一冊です。使われている数学は基本的なものでルベーグ積分も変分法も必要ありませんが、じっくり噛み締めながら勉強するのに適した本です。

人生なんてベイズエラーが相当大きくて、翻って考えると、回帰によって予測できる事態があり、法則が見つけられるのはキセキのように感じる。
なんてことを思いました。
いいねいいね